Kod ASCII to jeden z tych standardów, które wyglądają na historyczne, ale nadal porządkują ogromną część pracy z tekstem w systemach i oprogramowaniu. Poniżej wyjaśniam, jak działa ten 7-bitowy zapis znaków, jak czytać jego tabelę, które wartości warto zapamiętać i gdzie ASCII kończy się, a zaczyna Unicode oraz UTF-8. To praktyczna wiedza zarówno do analizy plików i logów, jak i do lepszego rozumienia terminali, API i protokołów tekstowych.
ASCII to 7-bitowy standard, który nadal porządkuje tekst między systemami
- ASCII opisuje 128 pozycji, czyli zakres od 0 do 127, a nie „dowolny tekst”.
- Najważniejsze są trzy grupy: znaki sterujące, cyfry oraz litery łacińskie.
- W UTF-8 znaki z zakresu 0x00-0x7F pozostają identyczne, dlatego ASCII wciąż jest bazą wielu formatów.
- Problemem w praktyce częściej jest złe kodowanie albo „extended ASCII” niż sam ASCII.
- Do codziennej pracy wystarczy znać kilka kluczowych kodów: spację, tabulator, nową linię, CR, cyfry i litery.
Czym jest ASCII i gdzie leży jego granica
ASCII jest standardem wymiany informacji między systemami: przypisuje liczbę do znaku albo do sygnału sterującego. W klasycznej wersji ma 7 bitów, więc opisuje 128 pozycji, od 0 do 127. Z tego 33 pozycje to znaki sterujące, a 95 to znaki drukowalne.
W praktyce najważniejsze jest to, że ASCII nie opisuje wyglądu litery, tylko jej numer. Dzięki temu ten sam tekst można zapisać, odczytać, porównać i przesłać między różnymi programami bez zgadywania, co oznacza dany bajt. W rejestrze IANA standard figuruje jako US-ASCII.
Ja patrzę na ASCII przede wszystkim jak na wspólny mianownik dla maszyn, które muszą dogadać się co do bardzo podstawowych znaków: liter łacińskich, cyfr, spacji i kilku symboli technicznych. Żeby dobrze z niego korzystać, trzeba jeszcze umieć czytać samą tabelę znaków, bo to tam kryje się cała praktyka.
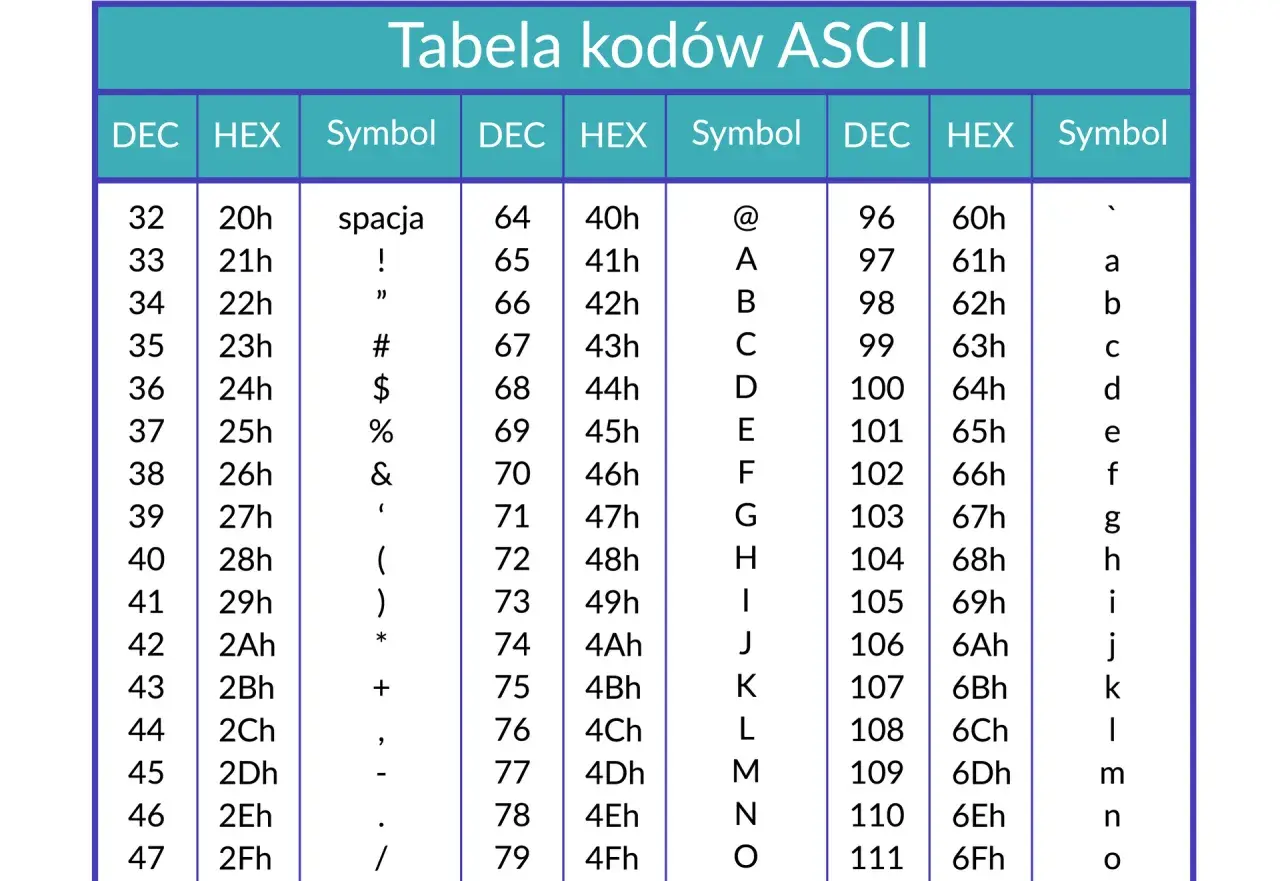
Jak czytać tablicę ASCII bez zgadywania
Najprostszy sposób to patrzeć na trzy zapisy tego samego znaku: dziesiętny, szesnastkowy i binarny. W kodzie źródłowym, w logach i w narzędziach diagnostycznych najczęściej zobaczysz zapis hex, bo jest krótszy i wygodnie pokazuje, do którego zakresu należy znak. Przykład: A = 65 = 0x41 = 01000001.
| Znak | Dziesiętnie | Szesnastkowo | Co warto wiedzieć |
|---|---|---|---|
| NUL | 0 | 0x00 | znak pusty, używany jako znacznik techniczny |
| TAB | 9 | 0x09 | tabulator, często w plikach tekstowych i terminalach |
| LF | 10 | 0x0A | nowa linia w systemach uniksowych i w wielu protokołach |
| CR | 13 | 0x0D | historyczny powrót karetki, dziś ważny głównie w CRLF |
| SP | 32 | 0x20 | spacja, pierwszy znak drukowalny |
| 0 | 48 | 0x30 | początek zakresu cyfr |
| 9 | 57 | 0x39 | koniec zakresu cyfr |
| A | 65 | 0x41 | początek wielkich liter |
| Z | 90 | 0x5A | koniec wielkich liter |
| a | 97 | 0x61 | początek małych liter |
| z | 122 | 0x7A | koniec małych liter |
| DEL | 127 | 0x7F | znak usuwania; historycznie ważny, ale niewidoczny |
Warto zapamiętać jeszcze jedną rzecz: w ASCII litery i cyfry układają się w logiczne, ciągłe bloki. To nie jest przypadek, tylko bardzo praktyczny projekt, który ułatwia porównywanie, walidację i podstawowe operacje na tekście. Jeśli chcesz wyłapać błędy w danych wejściowych, kolejnym krokiem są zakresy, które najczęściej wykorzystuje się w kodzie.
Najważniejsze zakresy, które warto zapamiętać
ASCII jest wygodny właśnie dlatego, że część zakresów jest ciągła. Programista nie musi szukać całej tabeli, żeby sprawdzić, czy coś jest cyfrą albo literą. Wystarczy znać kilka przedziałów:
- 0–31 oraz 127 to znaki sterujące; nie są „normalnym” tekstem, tylko instrukcjami dla urządzeń i programów.
- 32 to spacja, czyli pierwszy znak drukowalny.
- 48–57 to cyfry 0–9, a ich kolejność jest przewidywalna.
- 65–90 to wielkie litery A–Z.
- 97–122 to małe litery a–z.
Ten porządek ma realne konsekwencje. Dzięki niemu można pisać szybkie walidacje, prostą normalizację danych i porównania techniczne bez sięgania po cięższe mechanizmy. Trzeba tylko pamiętać, że takie porównania nie zastępują reguł językowych: w polskich znakach, sortowaniu lokalnym czy analizie nazw użytkowników ASCII nie wystarczy.
Jeśli chcesz wyłapać błędy w danych wejściowych, właśnie te granice najczęściej robią robotę. Następny krok to sprawdzenie, gdzie ten standard nadal jest użyteczny w nowoczesnych systemach.
Gdzie ASCII nadal robi robotę w systemach i oprogramowaniu
W nowoczesnym stacku ASCII pojawia się tam, gdzie trzeba porozumieć się bez tarcia: w terminalach, plikach konfiguracyjnych, logach i protokołach tekstowych. Składnia JSON, HTML, XML, SMTP czy HTTP opiera się na niewielkim zestawie znaków z podstawowego zakresu. Dzięki temu parser może bezdyskusyjnie rozpoznać nawias, cudzysłów, dwukropek albo znak końca linii.
- Terminale korzystają z kodów sterujących, sekwencji escape i znaków takich jak TAB, LF czy CR.
- Pliki konfiguracyjne często są czytane jako tekst, ale ich składnia nadal musi dać się opisać ASCII.
- Logi i debugowanie opierają się na prostych separatorach, które łatwo parsować i filtrować.
- Protokoły sieciowe potrzebują stabilnych separatorów i przewidywalnych znaków, zwłaszcza przy nagłówkach i liniach tekstowych.
To właśnie dlatego ASCII wciąż jest ważny nawet wtedy, gdy cały system pracuje już na Unicode. Granica między „tym, co jest danymi”, a „tym, co jest składnią”, często przebiega dokładnie przez podstawowy zakres znaków. I to prowadzi wprost do różnicy między ASCII, Unicode i UTF-8.
ASCII, Unicode i UTF-8 bez mylenia pojęć
Najwięcej problemów zaczyna się wtedy, gdy ktoś miesza trzy poziomy: repertuar znaków, sposób kodowania i wygląd czcionki. Unicode mówi, jaki znak istnieje. UTF-8 mówi, jak ten znak zapisać w bajtach. Czcionka decyduje dopiero o tym, jak znak wygląda na ekranie.
To ważne, bo tekst ASCII zapisany w UTF-8 pozostaje taki sam na poziomie bajtów w zakresie 0x00–0x7F. Dlatego starsze pliki i protokoły często działają bez zmian w nowoczesnym środowisku, a jednocześnie można do nich dołożyć znaki spoza podstawowego zestawu. W praktyce to właśnie ta zgodność wsteczna utrzymała ASCII przy życiu.
| Pojęcie | Rola | Co jest najważniejsze |
|---|---|---|
| ASCII | podstawowy 7-bitowy zestaw znaków | 128 pozycji, dobrze znane znaki techniczne i łacińskie |
| Unicode | uniwersalny repertuar znaków | obejmuje znaki z wielu języków i symbole |
| UTF-8 | sposób zapisu Unicode w bajtach | znaki ASCII zapisuje bez zmian, resztę koduje wielobajtowo |
W praktyce to oznacza prostą zasadę: jeżeli tekst ma być wielojęzyczny, trzymaj go w UTF-8; jeśli protokół lub stary format wymaga podstawowego zestawu znaków, pilnuj zakresu ASCII. Gdy to rozdzielisz, większość błędów związanych z tekstem staje się od razu łatwiejsza do namierzenia.
Najczęstsze pułapki przy pracy z tekstem
Najbardziej zdradliwy skrót myślowy to „extended ASCII”. W ścisłym sensie nie istnieje jeden jednolity rozszerzony ASCII, tylko zestawy stron kodowych, które różniły się między systemami i regionami. Jeśli ktoś mówi o „rozszerzonym ASCII”, zwykle trzeba dopytać, o które kodowanie chodzi naprawdę.
Druga pułapka to wczytywanie bajtów bez sprawdzenia deklarowanego kodowania. Gdy plik UTF-8 zostanie potraktowany jak 8-bitowy zestaw znaków, pojawia się klasyczne mojibake, czyli śmieciowe znaki. Trzecia rzecz to końce linii: LF, CRLF i rzadziej CR to ten sam problem oglądany z trzech historycznych perspektyw.
Jest jeszcze czwarta, bardzo częsta pomyłka: mylenie kodowania z wyglądem. Czcionka nie zmienia kodu znaku, tylko sposób jego prezentacji. Jeśli więc tekst wygląda dziwnie, to nie znaczy automatycznie, że problem leży po stronie ASCII; równie dobrze winne może być kodowanie, normalizacja albo błędny parser.
Ja przy takich danych trzymam prostą zasadę: ASCII sprawdzam na granicy systemu, a nie w środku aplikacji. Wewnątrz kodu i bazy zwykle wygodniej pracować na UTF-8, a ASCII zostawić tam, gdzie specyfikacja naprawdę tego wymaga.
Co warto zapamiętać, gdy tekst trafia między systemami
Jeśli projektujesz, testujesz albo naprawiasz system tekstowy, kilka reguł oszczędzi ci sporo czasu:
- Jeśli specyfikacja mówi o US-ASCII, trzymaj się zakresu
0x00–0x7F. - Jeśli tworzysz nowe aplikacje, domyślnym wyborem powinien być UTF-8.
- Jeśli analizujesz błąd, sprawdzaj najpierw kodowanie, potem separatory, a dopiero później logikę biznesową.
- Jeśli definiujesz API, jasno rozdzielaj dane tekstowe, znaki sterujące i zakończenia linii.
Dobrze rozumiany ASCII oszczędza czas, bo pokazuje, gdzie kończy się prosty interfejs tekstowy, a zaczyna złożoność współczesnego Unicode. Jeśli pracujesz z parserami, logami albo integracjami, traktuj te dwa poziomy jako elementy jednej infrastruktury, a nie konkurujące światy.