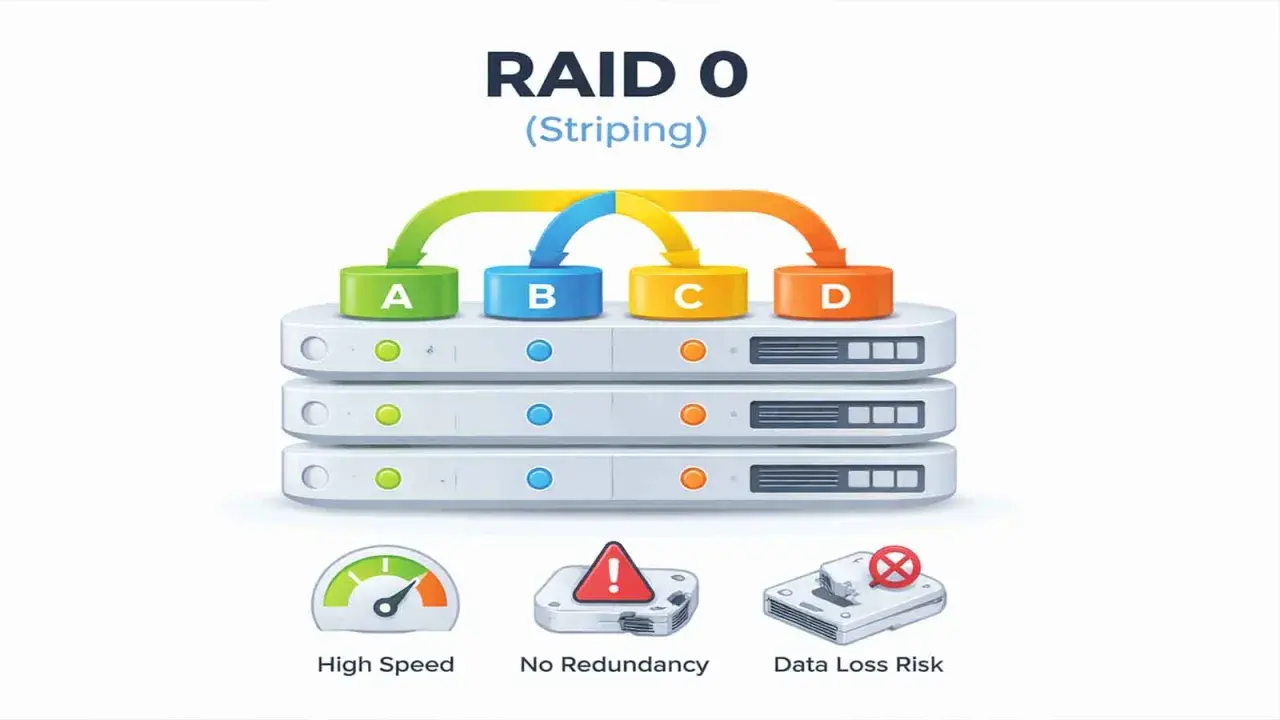
Striping na kilku dyskach kusi prostym efektem: większa przepustowość bez wymiany całej platformy. W praktyce rozwiązanie znane jako RAID 0 daje wyraźny zysk przy dużych plikach, ale jednocześnie zwiększa ryzyko utraty danych, więc decyzja ma sens tylko wtedy, gdy wiesz, do czego ten wolumin ma służyć. Poniżej rozkładam temat na konkretne wybory: jak działa, kiedy ma sens, jak dobrać nośniki i gdzie najczęściej pojawiają się kosztowne błędy.
Najważniejsze rzeczy o stripingu dysków
- Dane są dzielone na bloki i zapisywane równolegle na kilku nośnikach, więc rośnie przepustowość.
- Pojemność to suma dysków, ale awaria jednego z nich zwykle niszczy cały wolumin.
- Najlepiej sprawdza się przy dużych, sekwencyjnych plikach, na przykład przy montażu wideo, cache lub pracy z obrazami maszyn.
- W przypadku małych, losowych operacji zysk bywa dużo mniejszy niż sugerują marketingowe opisy.
- Backup jest obowiązkowy, bo ten układ nie zapewnia redundancji.
Jak działa striping i co to daje w praktyce
W tym układzie dane nie trafiają na jeden dysk po kolei, tylko są dzielone na równe bloki i rozrzucane po kilku nośnikach. Kontroler albo system operacyjny zapisuje kolejne fragmenty równolegle, więc przy dużym pliku kilka dysków pracuje jednocześnie zamiast czekać jeden na drugi.
Efekt jest prosty: rośnie przepustowość, zwłaszcza przy odczycie i zapisie dużych, ciągłych paczek danych. To nie oznacza jednak, że każdy scenariusz przyspieszy dwa razy. Przy małych plikach, wielu losowych zapisach i ograniczeniu po stronie CPU, magistrali lub systemu plików zysk może być umiarkowany albo prawie niewidoczny.
W praktyce dobrze widać to na pojemności. Jeśli zestawisz dwa dyski po 1 TB, dostaniesz 2 TB przestrzeni użytkowej. Jeśli połączysz 2 TB i 1 TB, i tak skończysz z 2 TB, bo większy nośnik oddaje tylko tyle, ile potrafi najmniejszy w zestawie. To ważne, bo mieszanie przypadkowych modeli często daje mniej sensu niż marketingowe obietnice. Następny krok to odpowiedź na pytanie, kiedy taki układ naprawdę ma sens.
Kiedy RAID 0 ma sens
To rozwiązanie wybieram tylko wtedy, gdy priorytetem jest tempo pracy, a dane można łatwo odtworzyć albo i tak istnieją w innej kopii. Najczęściej chodzi o zadania robocze, nie o archiwum. Z mojego punktu widzenia najlepiej sprawdza się w kilku scenariuszach:
- montaż i eksport wideo, gdzie pliki są duże i ciągłe,
- cache, scratch disk i katalogi robocze w programach graficznych,
- obrazy maszyn wirtualnych i środowiska testowe,
- gry i instalacje, jeśli ważniejszy jest szybki odczyt dużych zasobów niż bezpieczeństwo danych.
Jeśli jednak na tym woluminie mają leżeć jedyne kopie dokumentów, zdjęć rodzinnych, projektów klientów albo innych plików, których nie chcesz odtwarzać ręcznie, lepiej od razu szukać innego układu. To prowadzi do najważniejszego kompromisu, czyli związku między szybkością a ryzykiem.
Dlaczego wydajność rośnie, ale ryzyko też
Striping nie zawiera parzystości ani kopii lustrzanej. Parzystość to dodatkowe informacje, które pozwalają odtworzyć dane po awarii, a kopia lustrzana zapisuje te same dane na drugim nośniku. Tutaj nie ma ani jednego, ani drugiego. Jeśli padnie jeden dysk, cały wolumin przestaje być użyteczny.
W uproszczonym modelu ryzyko rośnie bardzo szybko wraz z liczbą nośników. Gdy przyjmiemy 2% rocznej awaryjności pojedynczego dysku, to dla dwóch dysków szansa, że w danym roku zawiedzie przynajmniej jeden, wynosi około 4%. Dla czterech dysków rośnie już do około 7,8%. To nie jest pełny model rzeczywistości, ale dobrze pokazuje kierunek: im więcej dysków, tym większa szansa na problem.
W realnym środowisku dochodzą jeszcze temperatura, jakość zasilania, wiek nośników i sposób użytkowania. Dlatego traktuję ten układ jak narzędzie do przyspieszania pracy, a nie jak sposób ochrony danych. Gdy już rozumiesz ten kompromis, warto dobrać sprzęt i konfigurację tak, żeby nie zmarnować potencjału.
Jak dobrać dyski i wdrożyć to w systemie
Na desktopach i stacjach roboczych striping najczęściej robi się programowo albo przez kontroler zintegrowany z platformą. To zwykle wystarcza, jeśli potrzebujesz po prostu szybszego woluminu roboczego. Ja zaczynam od trzech pytań: czy nośniki są podobne, czy system ma to obsłużyć bez problemów i czy wiem, jaki będzie typ danych.
- Dobierz możliwie podobne dyski. Najlepiej sprawdzają się modele o zbliżonej pojemności, klasie i interfejsie. Mieszanie bardzo różnych nośników zwykle sprawia, że całość zachowuje się jak najsłabszy element zestawu.
- Wybierz sposób wdrożenia. Jeśli zależy Ci na prostocie i niezależności od jednego kontrolera, software striping w systemie bywa wygodniejszy. Jeśli ważne są funkcje firmware i serwisowa obsługa na platformie producenta, kontroler może być lepszym wyborem.
- Ustal rozmiar paska pod typ plików. Jak podaje Dell, jeśli nie znasz średniego rozmiaru plików, 128 KB bywa sensownym punktem startowym. Przy dużych plikach roboczych taki wybór często działa lepiej niż przypadkowa wartość, a przy małych plikach zysk i tak będzie ograniczony.
- Testuj na kopii, nie na jedynej instalacji. Zanim przeniesiesz system lub ważne dane, sprawdź bootowanie, sterowniki i kopiowanie kilku rodzajów plików. Na papierze wszystko wygląda dobrze, ale dopiero praktyka pokazuje, czy konfiguracja faktycznie pomaga.
Jeśli miałbym wybrać jedną zasadę wdrożeniową, byłaby prosta: rozmiar paska dopasuj do przeciętnego pliku, a nie do intuicji. To drobiazg, który często decyduje o tym, czy zysk będzie zauważalny, czy rozmyje się w codziennej pracy. Dobrze widać to po porównaniu z innymi popularnymi układami.
Jak wypada na tle RAID 1 i RAID 10
Najczęstszy błąd to traktowanie stripingu jako uniwersalnego „przyspieszacza”. W praktyce ma on sens tylko w określonych warunkach, dlatego porównanie z dwoma innymi układami bardzo pomaga w decyzji.
| Układ | Co daje | Główna wada | Kiedy ma sens |
|---|---|---|---|
| Striping bez redundancji | Najwyższą przepustowość i pełną sumę pojemności nośników | Awaria jednego dysku oznacza utratę całego woluminu | Prace tymczasowe, cache, montaż, środowiska testowe |
| Kopia lustrzana | Odporność na awarię jednego nośnika | Połowa pojemności znika na duplikat danych | Dane ważne, małe serwery, systemy wymagające ciągłej dostępności |
| Układ łączący striping i mirroring | Łączy lepszą wydajność z odpornością na awarię jednego dysku | Wymaga co najmniej czterech dysków i oddaje połowę pojemności | Stacje robocze i serwery, gdzie liczy się i szybkość, i spokój |
Przykład liczbowy dobrze porządkuje temat: z dwóch dysków 1 TB dostajesz 2 TB w stripingu i 1 TB w kopii lustrzanej, a przy czterech dyskach 1 TB w układzie łączonym zostaje 2 TB przestrzeni użytkowej. Jeśli więc priorytetem nie jest wyłącznie szybkość, tylko równowaga między tempem pracy a bezpieczeństwem, wybór staje się prostszy. To również pokazuje, skąd biorą się typowe pomyłki.
Jakich błędów unikać przy konfiguracji
Widziałem kilka powtarzalnych potknięć, które potrafią zepsuć cały sens takiego zestawu. Najgroźniejsze z nich nie są technicznie skomplikowane, tylko zbyt łatwe do popełnienia:
- Mylenie wydajności z kopią zapasową. Szybszy wolumin nie chroni przed awarią, skasowaniem pliku ani ransomware.
- Łączenie przypadkowych dysków. Zestaw zbudowany z bardzo różnych nośników rzadko zachowuje się tak dobrze, jak sugeruje teoria.
- Oczekiwanie dwukrotnego przyspieszenia. Rzeczywisty zysk zależy od plików, sterowników, systemu plików i obciążenia całej platformy.
- Dobór zbyt dużego paska do małych plików. Jeśli większość pracy to drobne operacje, efekt może być słaby albo niezauważalny.
- Wdrażanie na jedynym systemie bez testu. Gdy coś pójdzie źle, koszt przestoju będzie większy niż korzyść z kilku dodatkowych procent wydajności.
Jeśli po tej liście nadal widzisz sens w szybszym woluminie, to dobrze. Chodzi właśnie o świadomy wybór, a nie o ślepe gonienie za liczbą dysków. Gdy jednak dane są ważne, częściej wybrałbym coś innego niż czysty striping.
Co wybrałbym, gdy zależy mi na szybkości i spokoju
Jeżeli potrzebuję głównie szybkości dla plików roboczych, a dane mogę łatwo odtworzyć, wybieram striping tylko dla konkretnego katalogu albo projektu, nie dla całego środowiska. Jeżeli dane są ważne, ale wydajność nadal ma znaczenie, rozsądniejszy jest układ łączący wydajność z odpornością albo pojedynczy bardzo szybki SSD z dobrym backupem i osobnym miejscem na cache.
Najwięcej problemów rozwiązuje nie samo dokładanie dysków, tylko sensowny podział ról: system, dane robocze, kopia zapasowa i wolumin tymczasowy to cztery różne zadania. Jeśli tak na to spojrzysz, łatwiej dobrać konfigurację, która przyspiesza pracę, ale nie zamienia awarii jednego nośnika w utratę wszystkiego.